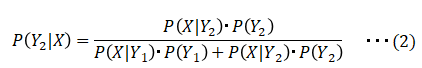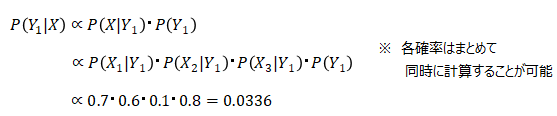単純ベイズ分類器(たんじゅんベイズぶんるいき、英: Naive Bayes classifier)は、単純な確率的分類器である。
概要
単純ベイズ分類器の元となる確率モデルは強い(単純な)独立性仮定と共にベイズの定理を適用することに基づいており、より正確に言えば「独立特徴モデル; independent feature model」と呼ぶべきものである。
確率モデルの性質に基づいて、単純ベイズ分類器は教師あり学習の設定で効率的に訓練可能である。多くの実用例では、単純ベイズ分類器のパラメータ推定には最尤法が使われる。つまり、単純ベイズ分類器を使用するにあたって、ベイズ確率やその他のベイズ的手法を使う必要はない。
設計も仮定も非常に単純であるにもかかわらず、単純ベイズ分類器は複雑な実世界の状況において、期待よりもずっとうまく働く。近頃、ベイズ分類問題の注意深い解析によって、単純ベイズ分類器の効率性に理論的理由があることが示された。単純ベイズ分類器の利点は、分類に不可欠なパラメータ(変数群の平均と分散)を見積もるのに、訓練例データが少なくて済む点である。変数群は独立であると仮定されているため、各クラスについての変数の分散だけが必要であり、共分散行列全体は不要である。
単純ベイズ確率モデル
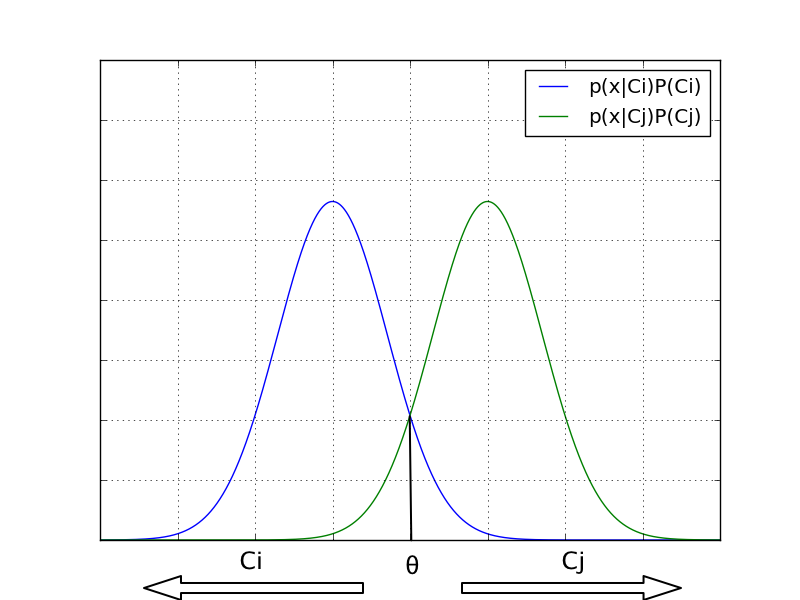
抽象的には、分類器の確率モデルは次のような依存クラス変数 についての条件付きモデルである。クラスは、いくつかの特徴変数 から までに依存している。
問題は、特徴数 が大きいとき、あるいは特徴がとりうる値の範囲が大きいとき、確率表に基づいたようなモデルは現実的でなくなることである。そこで、モデルをより扱いやすく変形する。
ベイズの定理を使えば、次のようになる。
この式を英語で表すと次のようになる(Posterior = 事後、Prior = 事前、Likelihood = 尤度、Evidence = 証拠)。
実際には、分母は に依存しておらず、分母が実質的に一定であるように が与えられるため、分子だけを考慮すればよい。分子は、次のように表される同時確率モデルと等価である。
これに条件付き確率の定義を繰り返し適用すると、次のように書き換えられる。
ここで、「単純」な条件付き独立性を仮定する。すなわち、各特徴変数 が条件付きで独立であるとする。独立性より、次の式が成り立つ。
すると、同時モデルは次のように表される。
つまり、上述のような独立性の仮定のもとで、クラス変数 の条件付き分布は次のように表される。
ここで、 は にのみ依存する係数であり、特徴変数群の値が既知であれば定数となる。
このようなモデルの方が扱いやすい。いわゆる「クラス事前確率」 と独立確率分布 に分かれているからである。 個のクラスがあり、 のモデルを 個のパラメータで表現できるとき、対応する単純ベイズモデルは (k − 1) n r k 個のパラメータを持つ。二項分類では であり、 は予測に使われる2値の特徴の個数である。
パラメータ推定
全てのモデルパラメータ(すなわち、クラス事前確率と特徴確率分布)は、訓練例の集合から相対度数によって見積もることができる。それらは確率の最尤推定量である。離散的でない特徴の場合、離散化を事前に行う必要がある。離散化には教師なし(場当たり的な手法)と教師あり(訓練データに基づいた手法)の手法がある。
あるクラスとある特徴値の組合せが訓練例では出現しない場合、度数に基づいた確率推定はゼロとなる。これを乗算に用いると積がゼロになってしまうという問題が生じる。これを防ぐため、確率値の推定をわずかに修正してどの組合せの確率値もゼロにならないようにすることが行われる(擬似カウント)。
確率モデルからの分類器構築
ここまでの説明で、独立特徴モデル、すなわち単純ベイズ確率モデルが導出された。単純ベイズ分類器はそのモデルに決定規則を合わせたものである。よく使われる決定規則は、最も事後確率が高い仮説を採用するというもので、最大事後確率(MAP)決定規則と呼ばれている。そのような分類器を関数 とすると、次のように表される。
議論
独立性を仮定することで、事後確率の計算結果が予期しないものとなる可能性を懸念する場合がある。観測結果に依存性がある状況では、確率に関する第二の公理、すなわち確率は常に 1 以下でなければならないという公理に反する結果が得られる可能性がある。
独立性の仮定を広範囲に適用することが正確性に欠けるという事実があるにもかかわらず、単純ベイズ分類器は実際には驚くほど有効である。特に、クラスの条件付き特徴分布を分離することは、各分布を1次元の分布として見積もることができることを意味している。そのため、特徴数が増えることで指数関数的に必要なデータ集合が大きくなるという「次元の呪い」から生じる問題を緩和できる。MAP 規則を使った確率的分類器の常として、正しいクラスが他のクラスより尤もらしい場合に限り、正しいクラスに到達する。それゆえ、クラス確率はうまく見積もられていなくてもよい。言い換えれば、根底にある単純な確率モデルの重大な欠陥を無効にするほど、分類器は全体として十分に頑健である。単純ベイズ分類器がうまく機能する理由についての議論は、後述の参考文献にもある。
例: 文書分類
単純ベイズ分類器を文書分類問題に適用した例を示す。文書群をその内容によって分類する問題であり、例えば、電子メールをスパム (C=0) とスパムでないもの (C=1) に分類する。文書は、単語群としてモデル化できるいくつかのクラスから取り出されるものとする。ここで、文書のi番目の単語 が、クラス C から取り出された文書に出現する(独立な)確率は、次のように書き表せる。
ただしこの式では、問題をより簡単にするため、単語は文書中にランダムに分布すると仮定している。すなわち、単語の出現確率は、文書の長さ、文書中での他の単語との位置関係、その他の文脈には依存しないものとする。
すると、あるクラスCが与えられた時、文書D が取り出される確率は次のようになる。
解きたい問題は、「ある文書 D が、あるクラス C に属する確率」であり、言い換えれば の値である。
ここで、定義から(確率空間参照)
かつ
となる。ベイズの定理によれば、尤度関数を使って確率が次のように表される。
ここで、クラスは S と ¬S の2つしかないと仮定する(例えば、スパムかそうでないか)。
かつ
となる。上記のベイズの結果を使うと、次のようになる。
一方を他方で割ると、次のようになる。
これを書き換えると、次の通り。
従って、確率比率 p(S | D) / p(¬S | D) は、一連の尤度比を使って表される。実際の確率 p(S | D) は、p(S | D) p(¬S | D) = 1 であることから、容易に log (p(S | D) / p(¬S | D)) から求められる。
これらの比を全て対数にすると、次の式が得られる。
統計学では、このような尤度比の対数を使うのが一般的な技法である。この例のような二項分類では、その値はシグモイド曲線を描く(ロジット参照)。
このようにして文書が分類される。 なら、その文書はスパムであり、そうでなければスパムではない。
Complement Naive Bayes
単純ベイズ分類機で、あるクラスに属さない補集合(英: Complement)を用いて学習させる拡張をComplement Naive Bayesという。
たとえば文章分類で純粋な単純ベイズ分類器では文章中のそのクラスに属する単語の出現率が大きくなってしまうが、属さない確率が最も低いクラスとして識別することで文章中のこのばらつきを最低限に抑えられる。これによってよい識別が可能になる。
脚注
参考文献
- Domingos, Pedro & Michael Pazzani (1997) "On the optimality of the simple Bayesian classifier under zero-one loss". Machine Learning, 29:103–137. (CiteSeer にあるオンライン版: [1])
- Rish, Irina. (2001). "An empirical study of the naive Bayes classifier". IJCAI 2001 Workshop on Empirical Methods in Artificial Intelligence. (オンライン版: PDF, PostScript)
- Hand, DJ, & Yu, K. (2001). "Idiot's Bayes - not so stupid after all?" International Statistical Review. Vol 69 part 3, pages 385-399. ISSN 0306-7734.
- Mozina M, Demsar J, Kattan M, & Zupan B. (2004). "Nomograms for Visualization of Naive Bayesian Classifier". In Proc. of PKDD-2004, pages 337-348. (オンライン版: PDF)
- Maron, M. E. (1961). "Automatic Indexing: An Experimental Inquiry." Journal of the ACM (JACM) 8(3):404–417. (オンライン版: PDF)
- Minsky, M. (1961). "Steps toward Artificial Intelligence." Proceedings of the IRE 49(1):8-30.
- McCallum, A. and Nigam K. "A Comparison of Event Models for Naive Bayes Text Classification". In AAAI/ICML-98 Workshop on Learning for Text Categorization, pp. 41-48. Technical Report WS-98-05. AAAI Press. 1998. (オンライン版: PDF)
- Harry Zhang "The Optimality of Naive Bayes". (オンライン版: PDF)
- S.Kotsiantis, P. Pintelas, Increasing the Classification Accuracy of Simple Bayesian Classifier, Lecture Notes in Artificial Intelligence, AIMSA 2004, Springer-Verlag Vol 3192, pp. 198-207, 2004 (PDF)
- S. Kotsiantis, P. Pintelas, Logitboost of Simple Bayesian Classifier, Computational Intelligence in Data mining Special Issue of the Informatica Journal, Vol 29 (1), pp. 53-59, 2005 (PDF)
関連項目
- サポートベクターマシン
- ニューラルネットワーク
- パーセプトロン
- ファジィ論理
- ブースティング
- ベイジアンネットワーク
- ベイズ推定
- MAP推定
- ロジスティック回帰
- 線形分類器
- 予測分析
外部リンク
- Hierarchical Naive Bayes Classifiers for uncertain data 単純ベイズ分類器の拡張の一種
- 単純ベイズ分類器を使ったオンラインアプリケーション Emotion Modelling
ソフトウェア
- Naive Bayes implementation in Visual Basic (ソースコードと実行ファイル)
- jBNC - Bayesian Network Classifier Toolbox
- POPFile Perl ベースのメール振り分けシステム。
- Statistical Pattern Recognition Toolbox for Matlab.